申明:这篇文章是阅读了medium给我进行推荐的一篇文章后写的总结材料,原文章在这里。
链式法则
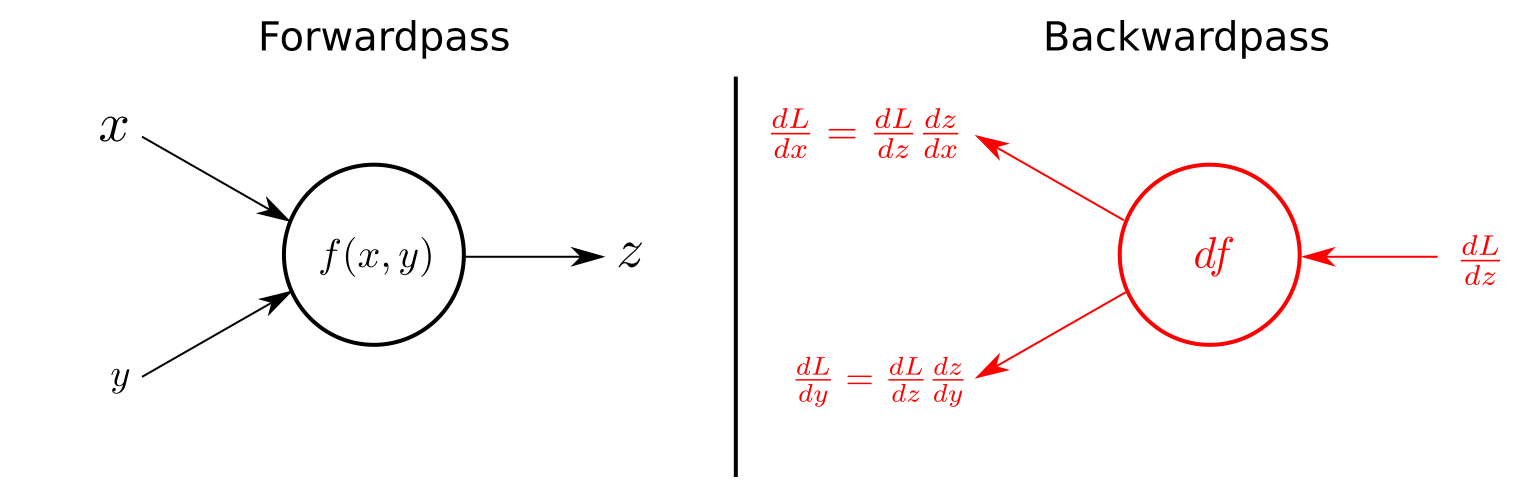
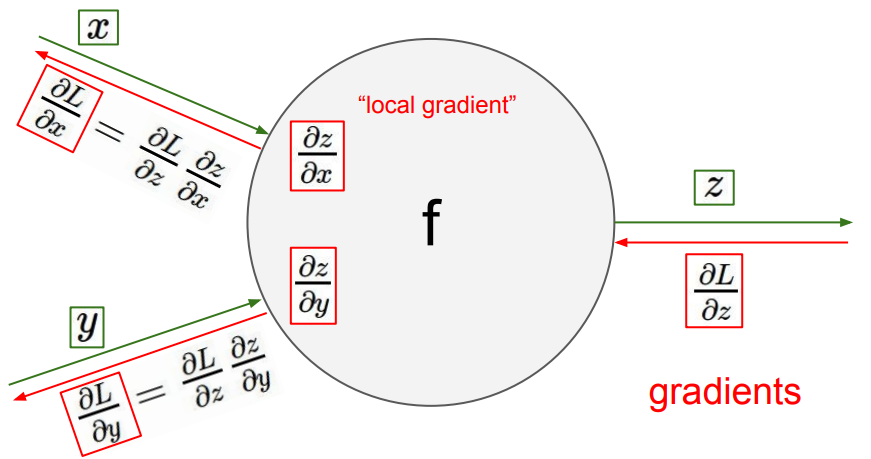
如果你理解了链式法则,那么我们可以继续了。
卷积神经网络
下面先给出一些结论,假设我们输入的某一层的数据长宽是$H \times W$,核的大小是$k$(假设核是正方形的),然后padding的大小是$p$,移动的步伐stride是$s$,那么我们下一层得到的数据的$h$是$$\frac{H-k+2p}{s} + 1$$同理下一层得到的数据的$w$是$$\frac{W-k+2p}{s} + 1$$
正向传播
为了理解卷积神经网络中的反向传播,我们假设输入输出的通道数是1。
下面的卷积图用了$3 \times 3$大小的输入数据,同时用了$2 \times 2$的卷积核,每次移动(stride)1步,并且没有padding填充,那么根据上面的公式,我们可以算出来这层经过卷积后输出数据的大小是$2 \times 2$的。为了理解反向传播,我们首先来看看正向传播是怎么样工作的。
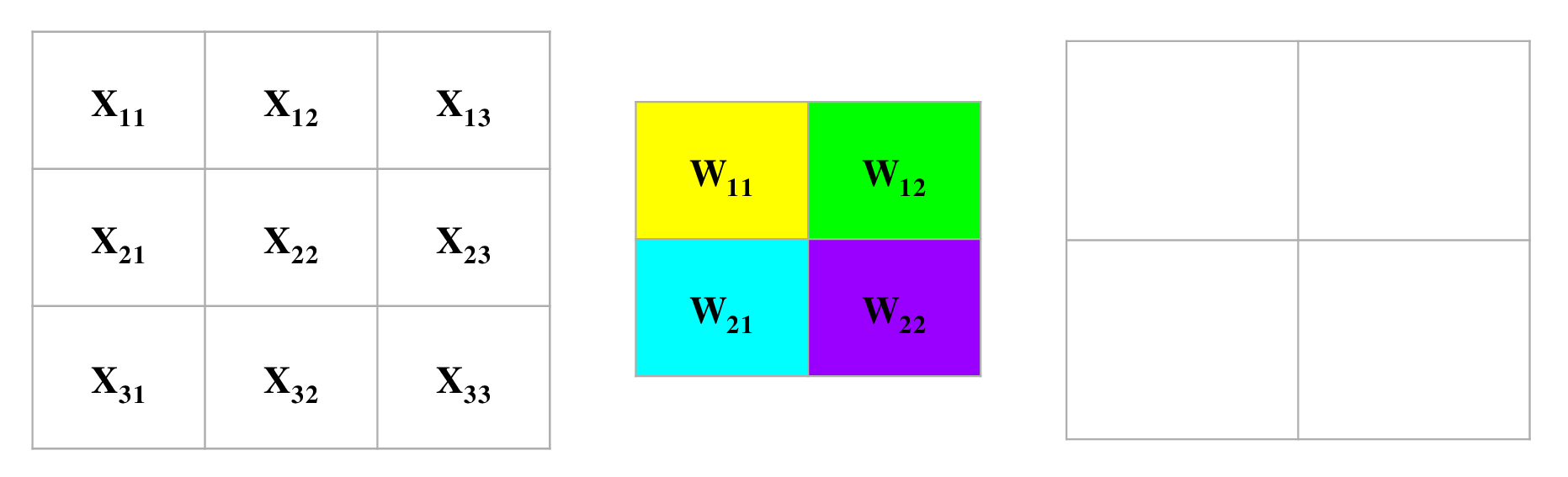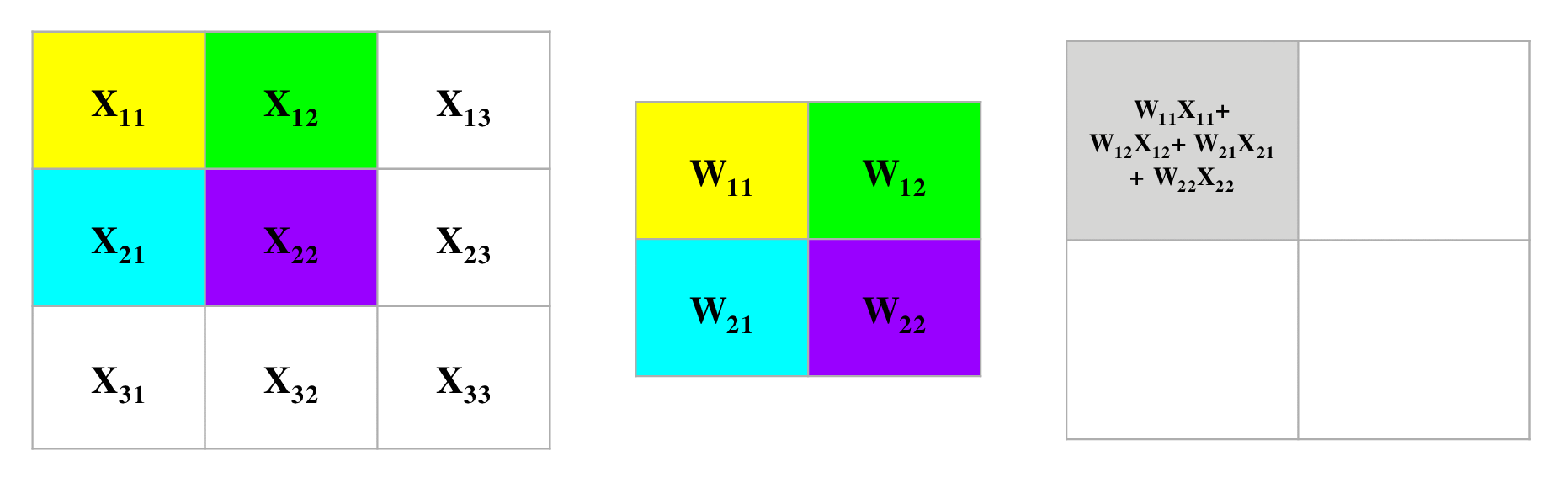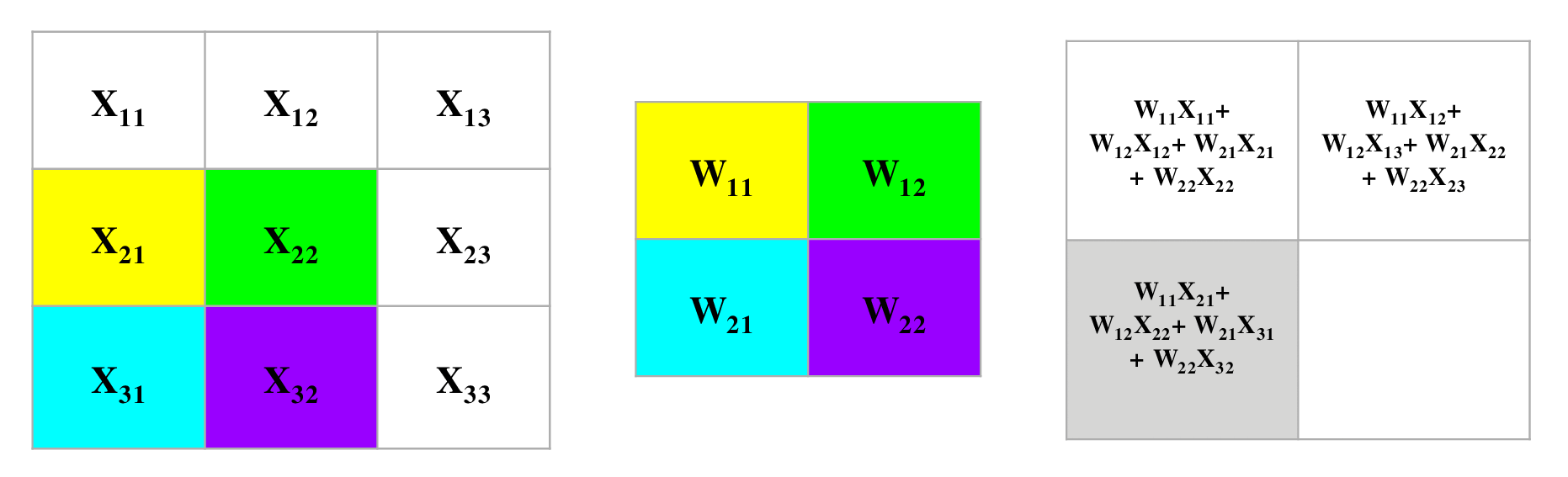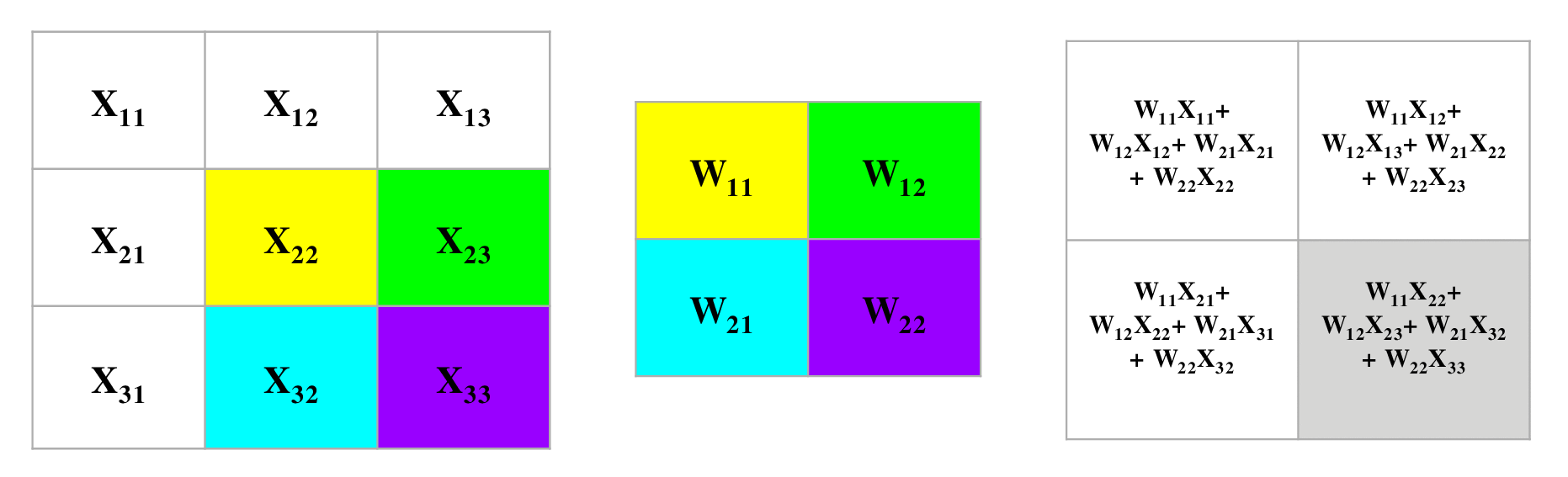
如图我们可以清楚的看到在进行正向卷积运算的全过程。
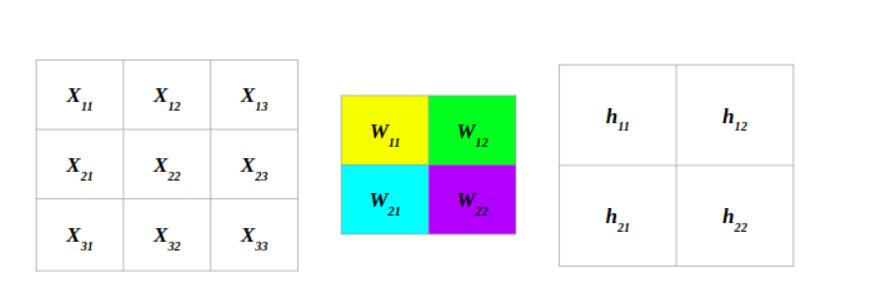
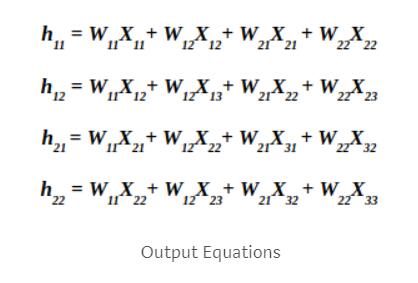
反向传播
在继续之前,让我们先来做一些约定.
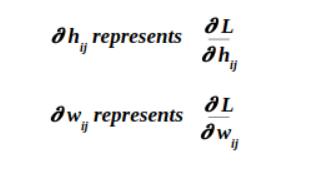
现在,让我们来实现反向传播算法,我们可以假设从后面一层穿回来的梯度误差是$\partial h$,然后我们要计算这一层中的导数$\partial x和\partial w$,为什么呢?因为计算$\partial w$可以让我们通过这一次反向传播更新这一层的参数$w$,而计算$\partial x$是因为这一层的数据是通过上一层计算得来的,所以要把梯度传回去,我们需要借助$x$这个媒介(如果是最开始的输入数据,比如第0层,就没必要计算了)。
这一层的每一个$w$参与计算了输出层的每一个$h$,所以说在更新每一个$w$的时候,要叠加传回来的所有$dh$的误差。如图所示。

接下来让我们一起来实现正向和反向传播算法.首先是导入数据
1 | import numpy as np |
然后进行正向传播1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def forward(X, w):
#得到长宽
height, width = X.shape
#得到核的大小
kernel_size = w.shape[0]
#根据公式算新的高度和宽度
new_height = (height - kernel_size) + 1
new_width = (width - kernel_size) + 1
#创建输出数据
out = np.zeros((new_height, new_width))
#卷积过程
for i in range(new_height):
for j in range(new_width):
#得到框里的数据
box = X[i:i+kernel_size, j:j+kernel_size]
#点积
out[i][j] = np.sum(w * box)
#将X和w存储起来,计算梯度的时候要用,还记得我们计算w的梯度的时候,每个框里的x和dh相乘吗?所以要把X存储起来
cache = [X, w]
return out, cache
传播1
2out, cache = forward(X, w)
print(out)
输出是
array([[ 12., 16.],
[ 24., 28.]])
我们可以手动计算来看一下,这是正确的。
然后进行反向传播1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#这里我们只计算dw
def backward(dH, cache):
#得到X
X, w = cache
new_height, new_width = dH.shape
kernel_size = w.shape[0]
#dw大小和w相同
dw = np.zeros_like(w)
#进行反向传播
for i in range(new_height):
for j in range(new_width):
#同理在X中得到框里的数据
box = X[i:i+kernel_size, j:j+kernel_size]
dw += box * dH[i][j]
return dw
1 | #假设传回来的梯度都是1 |
传播1
2dw = backward(dH, cache)
print(dw)
array([[ 12., 16.],
[ 24., 28.]])
通过手动计算,我们可以计算得出此梯度是正确的.
到此为止,我们就学会了卷积神经网络中的梯度流动。