intuition
在我们的现实生活中,常常会遇到如下的问题,比如说我通过一个人的一些面部特征,比如说眼睛的大小,皱纹的程度,头发的浓密情况(笑)等特征情况,来猜猜看这个人的岁数;又比如说我们是在银行工作,然后我们又想要通过一个人的一些日常情况,比如说他的存款数,按时守约数,家庭人员数量等特征来给他进行信用评分,然后来决定要不要给他发放信用卡。而在上述的两个问题有这样一个共同点,那就是我们拥有了一些来描述某个目标(比如人)的一些特征属型,然后来给这个目标一个分数,即我们通过一些特征,来得到一个分数,而这个分数是连续的数值,并且属于实数范围内,那么我们就可以将这个问题划分为一个回归问题。
那么机器学习中的回归问题又是指的是什么呢?让我们来回想一下我们中学时代的一些问题比如说我们刚学习函数y=x的时候,老师会说:小明,我告诉你x=1,那么你能告诉我y等于多少吗?那你会说,so easy啊,就是1嘛。然后老师又说那我任意给你一个数值,你都能知道是对应的y是多少吗?那你会说,知道啊,那你说x是多少y就是多少嘛,因为有公式y=x啊!好了,接下来,我们反过来看,假如说老师先给了你一些描述x和y对应关系的点,比如说老师告诉你x=1的时候y=1,x=3的时候y=3,x=100的时候y=100,然后老师对你说:小明,你能告诉老师y和x的对应关系吗??那你会说y=x啊老师。老师又说了,一定是y=x吗?这时候你就会想一想说不一定啊,那我只是在我看到的资料上面这个公式符合,但是并不一定能够适用于普遍情况啊,万一x=2时y=2.1呢。
所以说所谓的机器学习问题,就是说我们设计一个演算法(所谓的机器),然后给机器看我们已经有的数据,然后让机器自己去学习相对应的方法(即训练),等到训练后让我们告诉机器一个x的值,然后机器告诉我们y的值是多少,大体上来讲,机器学习所做的事,就是这样的简单。
而线性回归是机器学习的一种具体方法,怎么说呢,就像上面所说的我们看到了一些x和y的取值,那么我们得想一想办法将他们联系起来,但是我们又比较笨,只学了一些简单的函数比如说y=kx(k代表权重,未知值),那么我们就先用这个笨笨的表示法去猜一猜好了。对于文章刚开始的问题,我们可以重新这么定义,我们不是已经知道了目标的某些特征了吗,那么我们给每个特征一个权重值,代表它有多重要,那么在我们后续的打分中,权重大的特征给分数的影响就会大一些。
问题可以这么定义:我们要得到打分分数y,对于每个特征,我们分配相对应的权重w0,w1,w2…,那么最后的分数就是$w_0x_0 + w_1x_1 + w_2x_2…$啊,这和我们初中学的直线的表示方法也差不多嘛,不过是从$y=kx$变成了$y=k_1x_1+k_2x_2+k_3x_3$了,好了,那我们要怎么样自动找出来所需要的$w$值呢?
我们可以这样试试看,我先把现在打分得到的分数先拿到,然后跟真正的分数对比(比如说我们判断一个人年龄的时候,先收集好一些人的特征和他们对应的年龄),然后测量一下他们的差值,比如说我们用$$(h-y)^2$$来表示他们的差距,其中h是预测的分数,y是真正的分数,之所以用平方是因为如果两个值差的远的话,这样测出来的差距会很大,并且这个差距是非负的,而这个函数又比较简单。那么一个好的权值集合$w_1,w_2….$是什么样子的呢??那么理所当然的我们会想,就是让这个差距很小啊,要是0的话最好了,所以说我们就要来调整这些w的值使得这个差距越来越小。那么问题来了,要怎么样调整w的值呢???
好了,再次让我们回到初中来,假如说有一个函数是这样的,$差距=(w-2)^2$,你来选一个w的值使得差距最小,你会不会选啊?那么我们这里所做的工作不久是这样吗,回忆一下在这里$差距=(xw - y)^2$,那也是一样的啊,这里的x和y都是常数啊,是已经给我们的的数值了,到了这里你会说,哎呀,那我要求它的最小值,那我可以配方啊,但是高中的时候我们不是学过一种更快的方法吗,对$w$求导,然后让那个式子等于0解出来$w$的值就可以了啊。哇,你会说,原来机器学习求解的方法我们高中就学过了啊。
但是在这里我们并不用让导数等于0的方法来求最小值(虽然你也可以这么做),这里我们用梯度下降的方法来进行优化,而梯度下降,大家可以自己网上找一找教程博客来看看,其基础的思想其实很简单,在这里就不介绍了。总之我们同样是要对$w$求导,但是最后的时候我们不解$f(w)=0$而是直接更新$w$的值.

预备知识
好吧好吧,下面来交个大家一点所谓的大学知识,我们定义一个向量是数的集合,就是里面放了一堆数,然后都是竖的比如说
$$
a=
\left[
\begin{matrix}
1 \\
2 \\
3
\end{matrix}
\right]
$$
,然后转置,就是把一个向量放平,
$$a^T=
\left[
\begin{matrix}
1&2&3
\end{matrix}
\right]$$
同理,平的’向量’再转置,就变成了竖的。
然后就是向量相乘,一个平的向量乘上(dot)一个竖的向量,我们这样定义$a.dot(b)$,这个运算我们可以这么想,就是把平的向量放成竖的,然后在横的方向上高度相同的数值相乘,然后再把不同高度的数值累加起来(有点啰嗦,看例子)比如
$$
\left[
\begin{matrix}
a & b & c
\end{matrix}
\right]
\left[
\begin{matrix}
d \\
e \\
f
\end{matrix}
\right]=
\left[
\begin{matrix}
a \\
b \\
c
\end{matrix}
\right]*
\left[
\begin{matrix}
d \\
e \\
f
\end{matrix}
\right] =
ad+be+cf
$$
在这里我们做一个约定那就是有*的是对应位置相乘,没有的的是向量相乘。
踏上征途
现在我们有了一些大学的知识了,我们就可以继续我们的机器学习之旅了,首先我们将我们的权重放在一个向量里面,假设我们现在要预测一个人的年龄,有三个特征眼睛大小,脸部皱纹程度,头发浓密程度,他们各自有一个权重,那么我们现在的$$
w=
\left[
\begin{matrix}
w1 \\
w2 \\
w3
\end{matrix}
\right]
$$
,然后假设我们现在已经收集了三个人的数据了,数据如下
$$
X=
\left[
\begin{matrix}
眼大小&皱纹度&头发 \\
x11&x12&x13 \\
x21&x22&x23 \\
x31&x32&x33
\end{matrix}
\right],
y =
\left[
\begin{matrix}
y1 \\
y2 \\
y3
\end{matrix}
\right]
$$
因为有了我们刚才学过的向量知识,我们现在可以同时计算三个人的评分了,用$h=Xw$,这里我们不就是进行了三次平的向量与竖的向量的向量相乘吗?然后将得到的结果放在相应的位置,所以$$
Xw=
\left[
\begin{matrix}
x11w1+x12w2+x13w3 \\
x21w1+x22w2+x23w3 \\
x31w1+x32w2+x33w3
\end{matrix}
\right]
=h
$$
,然后用$(h-y)^2$就可以得到我们在每个样本上的差距,最后我们再把这些差距叠加起来就得到了总的差距了,这里我们得到的差错向量是3*1的大小,然后我们要把这些向量的差距加起来,最后得到一个总的差距量,还记得刚才我们解释的那个平的向量和竖的向量相乘的过程吗??如果这个平的向量和竖的向量是一样的那么
$$
\left[
\begin{matrix}
a&b&c
\end{matrix}
\right]
\left[
\begin{matrix}
a \\
b \\
c
\end{matrix}
\right]
=
\left[
\begin{matrix}
a \\
b \\
c
\end{matrix}
\right]*
\left[
\begin{matrix}
a \\
b \\
c
\end{matrix}
\right]
=a^2+b^2+c^2
$$
,OK,现在找到将这些差距叠加的方法了,我们将这个差距向量先放平然后再与原来的它相乘,我们就把这些差距的总和得到了。记得我们上一章中$$差距=(xw-y)^2$$吗,我们现在来看一下向量形式下它又长什么样子。上面的步骤合起来我们有总的差距$$loss=(Xw-y)^T(Xw-y)$$,这个式子中的$Xw-y$就是差距向量,而带T的是放平的,那么上面算出来的loss就是一个实数啦。
好了,根据上一章所说的我们只要对w求导,然后让它等于0,解出$w$是多少就好了嘛,而对于$w$的求导过程实际上就是遵循了一种称为链式法则的东西,就是你要对$w$求导,首先要对他上一层的东西东西求导,然后一层一层深入。好,为了给初学者进行求导的全貌,我们将上面的式子进行一步一步拆解,首先我们先得到预测值$$h=Xw$$,然后我们得到了差距值向量$$deff= h-y$$,最后将不同样本的差距值累加得到总的差距值$$loss=deff^Tdeff$$,然后我们要对$w$求导,我们首先得求$$ \frac{\partial loss}{\partial deff}$$,然后求$$ \frac{\partial deff}{\partial h}$$,最后求$$ \frac{\partial h}{\partial w}$$,即$$ \frac{\partial loss}{\partial w}= \frac{\partial loss}{\partial deff}\frac{\partial deff}{\partial h}\frac{\partial h}{\partial w}$$,这就是所谓的链式法则。
好的,首先我们先来求$$ \frac{\partial loss}{\partial deff}$$这一步的正向$$loss=deff^Tdeff$$实际上是在求向量每个点的平方和,所以说对它求导结果是$$2deff$$
接下来是$$deff = h-y$$,那么$$\frac{\partial deff}{\partial h}=1$$
最后是$$Xw=h$$,这一步比较麻烦,假设这时候我们已经从前两步传回来的$$dh= \frac{\partial loss}{\partial deff}\frac{\partial deff}{\partial h}$$。好的下面我们来看图,我们在这一步需要计算的是对$w$向量进行求导,那么我们首先来看看对$w_1$求导试试,在正向传播的时候,我们的$w_1$被用在了计算$h_1,h_2,h_3$,所以说当梯度传回来的时候$dh_1,dh_2,dh_3$都会将误差传给$w_1$,我们来看一下比如说$h_1$在被计算的时候是用了x的第一个行向量和w向量计算所得到的,那么$$\frac{\partial h1}{\partial w1}=x_{11}$$,再乘上我们对应的穿回来的梯度$dh_1$,那么这部分对$w1$的贡献就是$dh_1x_{11}$,而$w_1$参与计算了$h_1,h_2,h_3$,所以说$dw_1=dh_1 x_{11}+dh_2x_{21}+dh_3x_{31}$,那么我们可以总结出规律了,那就是你求对于列向量$w$求导,每一个位置上的导数值就是$X$中对应的列与$dh$的每个位置对应位置相乘,如图所示。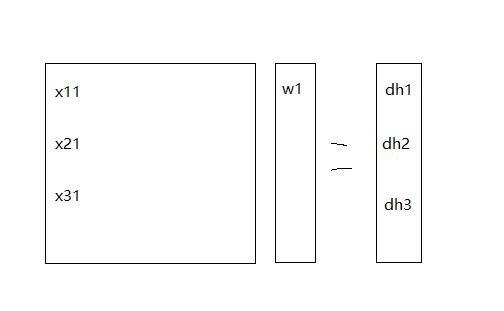
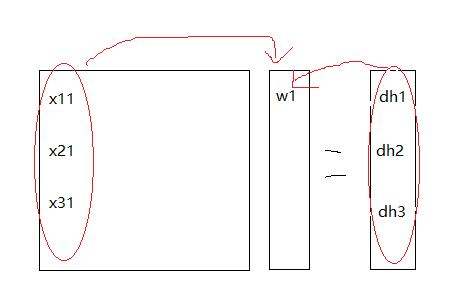
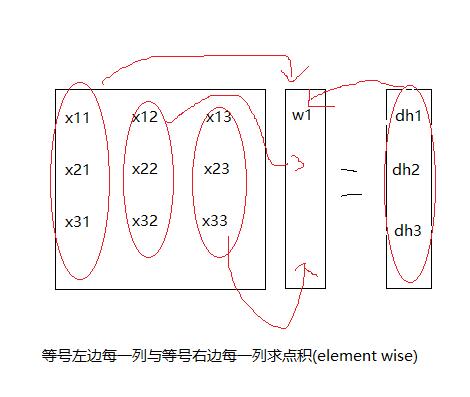
求点积的过程我们可以用$a^Ta$来代替,所以上式我们$$dh^TX$$就可以得到我们的$dw$,但是注意这时候得到的$dw$是平的,我们应该取转置,或者直接在求导的时候取转置,这样的话
$$
dw=X^Tdh
$$
好了,让我们把所有的东西加在一起,所以最后我们有
$$
\frac{\partial loss}{\partial w}=
\frac{\partial loss}{\partial deff}
\frac{\partial deff}{\partial h}
\frac{\partial h}{\partial w}=
X^Tdh=X^T*1*2deff = 2X^T(Xw-y)
$$
在这里我们让这个式子等于0,可以解出
$$
w=(X^TX)^{-1}X^Ty
$$
但是在这里我们打算用梯度下降的方法来进行优化,我们给定一定的学习速率lr,那么我们进行优化的公式就可以这么描述:$$w = w - lr \frac{\partial loss}{\partial w}$$
OK,到了这里你终于能够长舒一口气了,恭喜你已经走到了这一步。下面我们来你看看代码是怎么实现的。
首先我们先导入需要的包,然后创建一些假的数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import numpy as np
首先将我们的数据初始
'''
这里假设我们得到了一些人的特征X和相对应的标签y
比如这里得到了3个样本,每个样本有3个特征,而3个样本的分数分别是6,5,3
'''
X = np.array([[1,1,1],
[0,1,1],
[0,0,1]])
y = np.array([[6],
[5],
[3]])
print(X.shape)
print(y.shape)
'''
初始化权重,这里简单的初始成为了0,因为每个人有3个特征(3列),所以w的维度是3*1
'''
w = np.zeros((3, 1))
print(w)
'''
然后我们计算 h = X * w 的值,在这里矩阵相乘的话用np.dot()函数
'''
h = X.dot(w)
'''
这里得到的h是我们预测完的坐标向量,然后我们要用它和真实的坐标向量进行对比并计算损失
'''
deff = h - y
'''
下一步我们应该计算出总的差距值,用一个向量的转置乘上它自身以得到损失和
'''
loss = deff.T.dot(deff)
'''
打印损失
'''
print(loss)
'''
然后进行反向传播,首先求ddeff
'''
ddeff = 2 * deff
'''
然后是根据公式dh = 1 * ddeff
'''
dh = 1 * ddeff
'''
然后计算dw
'''
dw = X.T.dot(dh)
'''
这样就完成了一次反向传播
'''
1 | ''' |
out:
[[ 70.]]
[[ 0.0078892]]
[[ 0.00078922]]
[[ 0.00011647]]
[[ 2.53712989e-05]]
[[ 6.73698338e-06]]
[[ 1.91013569e-06]]
[[ 5.51543066e-07]]
[[ 1.60022359e-07]]
[[ 4.64861570e-08]]1
2
3
4'''
可以看到我们的损失是一直在降低的,同时我们查看w的值可以发现它学到的权重如下,这个这个权重在我们的样本X和预测y上完美符合,这说明我们的机器已经学习到了最适合它的参数
'''
print(w)
array([[ 0.99987689],
[ 2.00015464],
[ 2.99993077]])
1 | ''' |
可以看到我们上述的三个方法都得到了 $w_1=1,w_2=2,w_3=3$ 的结果,而这个参数正好吻合了训练集
`